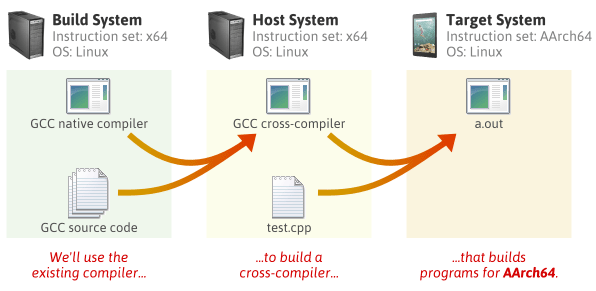
1
2
3
4
5
6
7
8
9
10
11
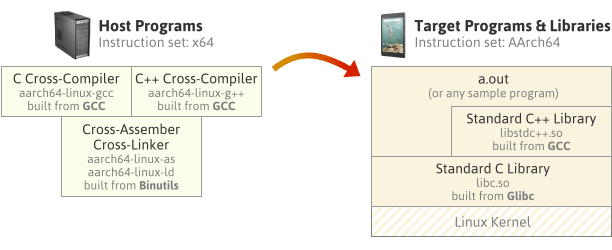
12
13
14
15
16
17
18
19
20
21
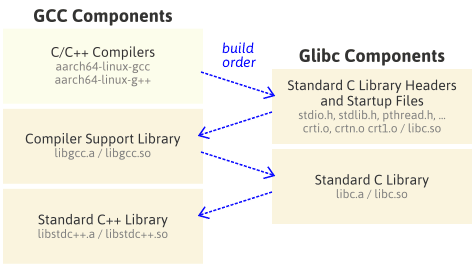
22
23
24
25
26
27
28
29
30
31
| router:~# tcpdump '(dst 192.168.10.2 && dst port 12345) || (src 192.168.10.2 && src port 12345)' -e
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), snapshot length 262144 bytes
17:33:45.712751 00:0c:29:06:c7:7e (oui Unknown) > 00:0c:29:65:3c:a3 (oui Unknown), ethertype IPv4 (0x0800), length 74: 192.168.10.2.12345 > 192.168.20.2.10080: Flags [S], seq 4018363570, win 64240, options [mss 1460,sackOK,TS val 1510067563 ecr 0,nop,wscale 7], length 0
17:33:45.712870 00:0c:29:65:3c:ad (oui Unknown) > 00:0c:29:5b:89:3e (oui Unknown), ethertype IPv4 (0x0800), length 74: 192.168.10.2.12345 > 192.168.20.2.10080: Flags [S], seq 4018363570, win 64240, options [mss 1460,sackOK,TS val 1510067563 ecr 0,nop,wscale 7], length 0
17:33:45.713459 00:0c:29:5b:89:3e (oui Unknown) > 00:0c:29:65:3c:ad (oui Unknown), ethertype IPv4 (0x0800), length 74: 192.168.10.2.12345 > 192.168.30.2.10080: Flags [S], seq 4018363570, win 64240, options [mss 1460,sackOK,TS val 1510067563 ecr 0,nop,wscale 7], length 0
17:33:45.713460 00:0c:29:65:3c:b7 (oui Unknown) > 00:0c:29:15:da:6a (oui Unknown), ethertype IPv4 (0x0800), length 74: 192.168.10.2.12345 > 192.168.30.2.10080: Flags [S], seq 4018363570, win 64240, options [mss 1460,sackOK,TS val 1510067563 ecr 0,nop,wscale 7], length 0
17:33:45.713557 00:0c:29:15:da:6a (oui Unknown) > 00:0c:29:65:3c:b7 (oui Unknown), ethertype IPv4 (0x0800), length 74: 192.168.20.2.10080 > 192.168.10.2.12345: Flags [S.], seq 4008910075, ack 4018363571, win 65160, options [mss 1460,sackOK,TS val 3299425652 ecr 1510067563,nop,wscale 7], length 0
17:33:45.713572 00:0c:29:65:3c:a3 (oui Unknown) > 00:0c:29:06:c7:7e (oui Unknown), ethertype IPv4 (0x0800), length 74: 192.168.20.2.10080 > 192.168.10.2.12345: Flags [S.], seq 4008910075, ack 4018363571, win 65160, options [mss 1460,sackOK,TS val 3299425652 ecr 1510067563,nop,wscale 7], length 0
17:33:45.713802 00:0c:29:06:c7:7e (oui Unknown) > 00:0c:29:65:3c:a3 (oui Unknown), ethertype IPv4 (0x0800), length 66: 192.168.10.2.12345 > 192.168.20.2.10080: Flags [.], ack 1, win 502, options [nop,nop,TS val 1510067564 ecr 3299425652], length 0
17:33:45.713907 00:0c:29:65:3c:ad (oui Unknown) > 00:0c:29:5b:89:3e (oui Unknown), ethertype IPv4 (0x0800), length 66: 192.168.10.2.12345 > 192.168.20.2.10080: Flags [.], ack 1, win 502, options [nop,nop,TS val 1510067564 ecr 3299425652], length 0
17:33:45.714096 00:0c:29:5b:89:3e (oui Unknown) > 00:0c:29:65:3c:ad (oui Unknown), ethertype IPv4 (0x0800), length 66: 192.168.10.2.12345 > 192.168.30.2.10080: Flags [.], ack 4008910076, win 502, options [nop,nop,TS val 1510067564 ecr 3299425652], length 0
17:33:45.714207 00:0c:29:65:3c:b7 (oui Unknown) > 00:0c:29:15:da:6a (oui Unknown), ethertype IPv4 (0x0800), length 66: 192.168.10.2.12345 > 192.168.30.2.10080: Flags [.], ack 1, win 502, options [nop,nop,TS val 1510067564 ecr 3299425652], length 0
17:33:49.369321 00:0c:29:06:c7:7e (oui Unknown) > 00:0c:29:65:3c:a3 (oui Unknown), ethertype IPv4 (0x0800), length 72: 192.168.10.2.12345 > 192.168.20.2.10080: Flags [P.], seq 1:7, ack 1, win 502, options [nop,nop,TS val 1510071219 ecr 3299425652], length 6
17:33:49.369451 00:0c:29:65:3c:ad (oui Unknown) > 00:0c:29:5b:89:3e (oui Unknown), ethertype IPv4 (0x0800), length 72: 192.168.10.2.12345 > 192.168.20.2.10080: Flags [P.], seq 1:7, ack 1, win 502, options [nop,nop,TS val 1510071219 ecr 3299425652], length 6
17:33:49.369819 00:0c:29:5b:89:3e (oui Unknown) > 00:0c:29:65:3c:ad (oui Unknown), ethertype IPv4 (0x0800), length 72: 192.168.10.2.12345 > 192.168.30.2.10080: Flags [P.], seq 0:6, ack 1, win 502, options [nop,nop,TS val 1510071219 ecr 3299425652], length 6
17:33:49.369820 00:0c:29:65:3c:b7 (oui Unknown) > 00:0c:29:15:da:6a (oui Unknown), ethertype IPv4 (0x0800), length 72: 192.168.10.2.12345 > 192.168.30.2.10080: Flags [P.], seq 0:6, ack 1, win 502, options [nop,nop,TS val 1510071219 ecr 3299425652], length 6
17:33:49.370069 00:0c:29:15:da:6a (oui Unknown) > 00:0c:29:65:3c:b7 (oui Unknown), ethertype IPv4 (0x0800), length 66: 192.168.20.2.10080 > 192.168.10.2.12345: Flags [.], ack 7, win 510, options [nop,nop,TS val 3299429309 ecr 1510071219], length 0
17:33:49.370087 00:0c:29:65:3c:a3 (oui Unknown) > 00:0c:29:06:c7:7e (oui Unknown), ethertype IPv4 (0x0800), length 66: 192.168.20.2.10080 > 192.168.10.2.12345: Flags [.], ack 7, win 510, options [nop,nop,TS val 3299429309 ecr 1510071219], length 0
17:33:51.689563 00:0c:29:06:c7:7e (oui Unknown) > 00:0c:29:65:3c:a3 (oui Unknown), ethertype IPv4 (0x0800), length 72: 192.168.10.2.12345 > 192.168.20.2.10080: Flags [P.], seq 7:13, ack 1, win 502, options [nop,nop,TS val 1510073539 ecr 3299429309], length 6
17:33:51.689687 00:0c:29:65:3c:ad (oui Unknown) > 00:0c:29:5b:89:3e (oui Unknown), ethertype IPv4 (0x0800), length 72: 192.168.10.2.12345 > 192.168.20.2.10080: Flags [P.], seq 7:13, ack 1, win 502, options [nop,nop,TS val 1510073539 ecr 3299429309], length 6
17:33:51.690131 00:0c:29:5b:89:3e (oui Unknown) > 00:0c:29:65:3c:ad (oui Unknown), ethertype IPv4 (0x0800), length 72: 192.168.10.2.12345 > 192.168.30.2.10080: Flags [P.], seq 6:12, ack 1, win 502, options [nop,nop,TS val 1510073539 ecr 3299429309], length 6
17:33:51.690131 00:0c:29:65:3c:b7 (oui Unknown) > 00:0c:29:15:da:6a (oui Unknown), ethertype IPv4 (0x0800), length 72: 192.168.10.2.12345 > 192.168.30.2.10080: Flags [P.], seq 6:12, ack 1, win 502, options [nop,nop,TS val 1510073539 ecr 3299429309], length 6
17:33:51.690297 00:0c:29:15:da:6a (oui Unknown) > 00:0c:29:65:3c:b7 (oui Unknown), ethertype IPv4 (0x0800), length 66: 192.168.20.2.10080 > 192.168.10.2.12345: Flags [.], ack 13, win 510, options [nop,nop,TS val 3299431629 ecr 1510073539], length 0
17:33:51.690305 00:0c:29:65:3c:a3 (oui Unknown) > 00:0c:29:06:c7:7e (oui Unknown), ethertype IPv4 (0x0800), length 66: 192.168.20.2.10080 > 192.168.10.2.12345: Flags [.], ack 13, win 510, options [nop,nop,TS val 3299431629 ecr 1510073539], length 0
17:33:55.442820 00:0c:29:06:c7:7e (oui Unknown) > 00:0c:29:65:3c:a3 (oui Unknown), ethertype IPv4 (0x0800), length 66: 192.168.10.2.12345 > 192.168.20.2.10080: Flags [F.], seq 13, ack 1, win 502, options [nop,nop,TS val 1510077293 ecr 3299431629], length 0
17:33:55.442935 00:0c:29:65:3c:ad (oui Unknown) > 00:0c:29:5b:89:3e (oui Unknown), ethertype IPv4 (0x0800), length 66: 192.168.10.2.12345 > 192.168.20.2.10080: Flags [F.], seq 13, ack 1, win 502, options [nop,nop,TS val 1510077293 ecr 3299431629], length 0
17:33:55.443307 00:0c:29:5b:89:3e (oui Unknown) > 00:0c:29:65:3c:ad (oui Unknown), ethertype IPv4 (0x0800), length 66: 192.168.10.2.12345 > 192.168.30.2.10080: Flags [F.], seq 12, ack 1, win 502, options [nop,nop,TS val 1510077293 ecr 3299431629], length 0
17:33:55.443307 00:0c:29:65:3c:b7 (oui Unknown) > 00:0c:29:15:da:6a (oui Unknown), ethertype IPv4 (0x0800), length 66: 192.168.10.2.12345 > 192.168.30.2.10080: Flags [F.], seq 12, ack 1, win 502, options [nop,nop,TS val 1510077293 ecr 3299431629], length 0
17:33:55.486509 00:0c:29:15:da:6a (oui Unknown) > 00:0c:29:65:3c:b7 (oui Unknown), ethertype IPv4 (0x0800), length 66: 192.168.20.2.10080 > 192.168.10.2.12345: Flags [.], ack 14, win 510, options [nop,nop,TS val 3299435425 ecr 1510077293], length 0
17:33:55.486527 00:0c:29:65:3c:a3 (oui Unknown) > 00:0c:29:06:c7:7e (oui Unknown), ethertype IPv4 (0x0800), length 66: 192.168.20.2.10080 > 192.168.10.2.12345: Flags [.], ack 14, win 510, options [nop,nop,TS val 3299435425 ecr 1510077293], length 0
|








{kind=link}